KNN入门
最近开始学习机器学习的有关知识,对于初学者来说,KNN算法因朴素的思想其被认为是最适合入门的机器学习算法,没有之一。本篇文章主要介绍KNN算法的基本知识与核心思想。
1、KNN简介
kNN (k-NearestNeighbor),也就是k最近邻算法,这是一种有监督的学习算法,该算法既可以针对离散因变量做分类,又可以对连续因变量做预测
2、核心思想
近朱者赤,近墨者黑
举个简单的例子,以下是支付宝对芝麻信用分的定义:
依据用户各类消费及行为数据,结合互联网金融借贷信息,运用云计算及机器学习等技术,通过逻辑回归、决策树、随机森林等模型算法,对各维度数据进行综合处理和评估,在用户信用历史、行为偏好、履约能力、身份特质、人脉关系五个维度客观呈现个人信用状况的综合分值。
注意人脉关系这个维度,用通俗的话说就是你好友中混的最差的哥们都开玛莎拉蒂,月消费几十万,那么你的消费履约能力应该也不差
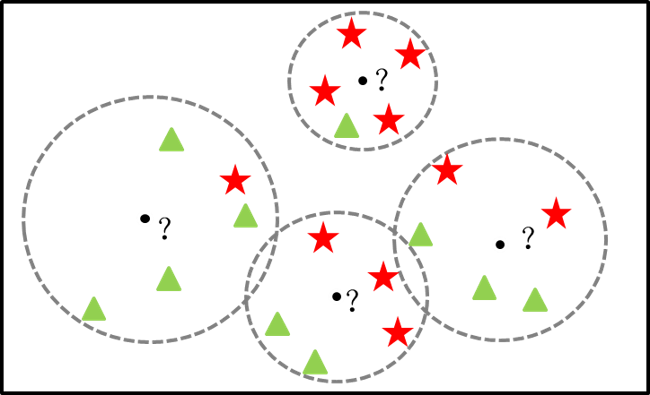
如图所示,KNN算法的本质就是寻找𝑘个最近样本,然后基于最近样本做“预测”。对于离散型的因变量来说,从𝑘个最近的已知类别样本中挑选出频率最高的类别用于未知样本的判断;对于连续型的因变量来说,则是将𝑘个最近的已知样本均值用作未知样本的预测。
3、算法步骤&关键点
- 确定未知样本近邻的个数𝑘值。
- 根据某种度量样本间相似度的指标(如欧氏距离)将每一个未知类别样本的最近𝑘个已知样本搜寻出来,形成一个个簇。
- 对搜寻出来的已知样本进行投票,将各簇下类别最多的分类用作未知样本点的预测。
3.1、K值的选择
根据经验发现,不同的𝑘值对模型的预测准确性会有比较大的影响,如果𝑘值过于偏小,可能会导致模型的过拟合;反之,又可能会使模型进入欠拟合状态。
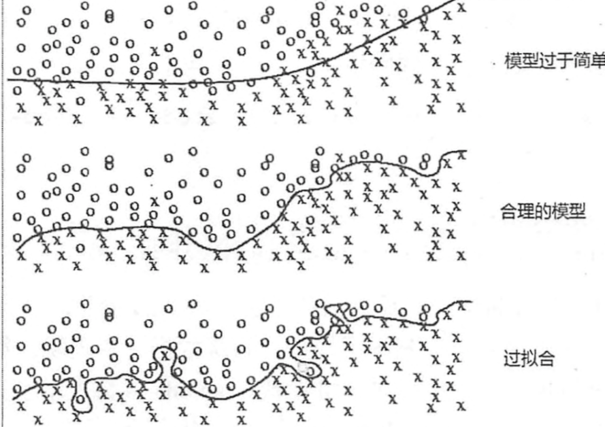
以芝麻分的例子来说,是选取你所有的好友来推断你的信用呢还是选取经常和你有金钱或信息来往的人进行推断呢?
目前有两种K值选择方案:
第一种:设置k近邻样本的投票权重,假设读者在使用KNN算法进行分类或预测时设置的k值比较大,担心模型发生欠拟合的现象,一个简单有效的处理办法就是设置近邻样本的投票权重,如果已知样本距离未知样本比较远,则对应的权重就设置得低一些,否则权重就高一些,通常可以将权重设置为距离的倒数。
第二种:采用多重交叉验证法,该方法是目前比较流行的方案,其核心就是将k取不同的值,然后在每种值下执行m重的交叉验证,最后选出平均误差最小的k值。
3.2、样本间相似度的度量方法
前面说到可以根据样本距离的远近设置对应的权重,那么如果计算样本之间的距离呢?一下有三种计算样本间距离的方法:
3.2.1、欧式距离
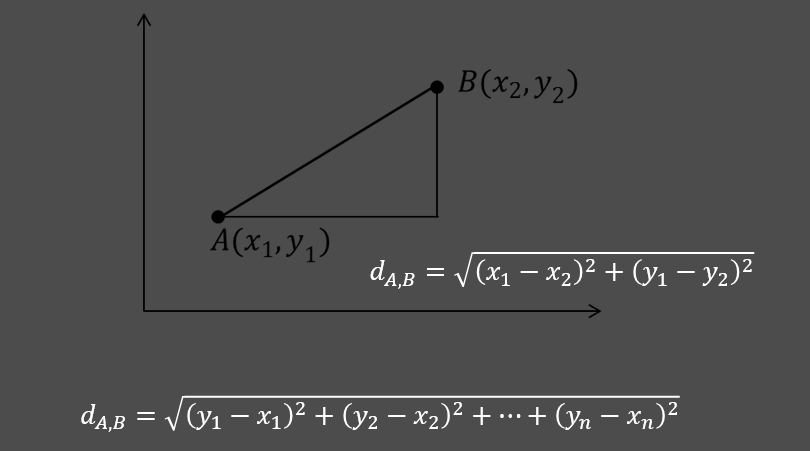
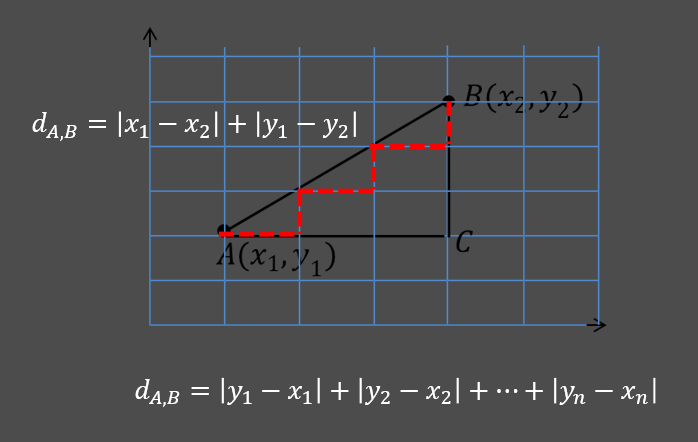
3.2.2、曼哈顿距离
3.2.3、余弦相似度
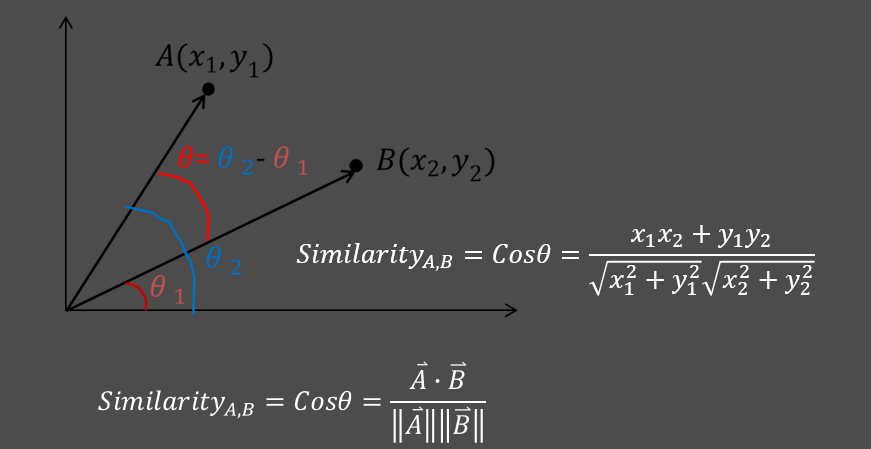
3.2.4、杰卡德相似系数
杰卡德相似系数与余弦相似度经常被用于推荐算法,计算用户之间的相似性。例如,A用户购买了10件不同的商品,B用户购买了15件不同的商品,则两者之间的相似系数可以表示为:
$$J(A,B)=\displaystyle \frac {|A \cap B|}{|A \cup B|}$$
其中,|A⋂B|表示两个用户所购买相同商品的数量,|A⋃B|代表两个用户购买所有产品的数量。例如,A用户购买的10件商品中有8件与B用户一致,且两个用户一共购买了17件不同的商品,则它们的杰卡德相似系数为8/17。



