K-Means聚类算法
Kmeans聚类的思想和原理
模型介绍
对于有监督的数据挖掘算法而言,数据集中需要包含标签变量(即因变量y的值)。但在有些场景下,并没有给定的y值,对于这类数据的建模,一般称为无监督的数据挖掘算法,最为典型的当属聚类算法。
Kmeans聚类算法利用距离远近的思想将目标数据聚为指定的k个簇,进而使样本呈现簇内差异小,簇间差异大的特征。
聚类过程
- 从数据中随机挑选k个样本点作为原始的簇中心
- 计算剩余样本与簇中心的距离,并把各样本标记为离k个簇中心最近的类别
- 重新计算各簇中样本点的均值,并以均值作为新的k个簇中心
- 不断重复第二步和第三步,直到簇中心的变化趋于稳定,形成最终的k个簇
原理介绍
在Kmeans聚类模型中,对于指定的k个簇,只有簇内样本越相似,聚类效果才越好。基于这个思想,可以理解为簇内样本的离差平方和之和达到最小即可。进而可以衍生出Kmeans聚类的目标函数:
$$
J(c_1,c_2,…c_k)={\sum_{j=1}^{k}\sum_{i}^{n_j}(x_{i}-{c_j})^2}
$$
其中,$c_j$表示第j个簇的簇中心,$x_i$属于第j个簇的样本i,$n_j$表示第j个簇的样本总量。对于该目标函数而言,$c_j$是未知的参数,要想求得目标函数的最小值,得先知道参数$c_j$的值。
求解参数$𝑐_𝑗$
1、对目标函数求偏导
$$
\frac{\partial J}{\partial c_{j}}=\sum_{j=1}^{k} \sum_{i=1}^{n_{j}} \frac{\left(x_{i}-c_{j}\right)^{2}}{\partial c_{j}}=\sum_{i=1}^{n_{j}} \frac{\left(x_{i}-c_{j}\right)^{2}}{\partial c_{j}}=\sum_{i=1}^{n_{j}}-2\left(x_{i}-c_{j}\right)
$$
2、令导数为0
$$
\begin{array}{l}{\sum_{i=1}^{n_{j}}-2\left(x_{i}-c_{j}\right)=0} \ {n_{j} c_{j}-\sum_{i=1}^{n_{j}} x_{i}=0} \ {\therefore c_{j}=\frac{\sum_{i=1}^{n_{j}} x_{i}}{n_{j}}=\mu_{j}}\end{array}
$$
Scikit-learn中的KMeans函数
KMeans(n_clusters=8, init='k-means++', n_init=10,
max_iter=300, tol=0.0001,
precompute_distances='auto',
verbose=0, random_state=None,copy_x=True,
n_jobs=1, algorithm='auto')n_clusters:用于指定聚类的簇数
init:用于指定初始的簇中心设置方法,如果为’k-means++’,则表示设置的初始簇中心之间相距较远;如果为’random’,则表示从数据集中随机挑选k个样本作为初始簇中心;如果为数组,则表示用户指定具体的簇中心
n_init:用于指定Kmeans算法运行的次数,每次运行时都会选择不同的初始簇中心,目的是防止算法收敛于局部最优,默认为10
max_iter:用于指定单次运行的迭代次数,默认为300
tol:用于指定算法收敛的阈值,默认为0.0001
precompute_distances:bool类型的参数,是否在算法运行之前计算样本之间的距离,默认为’auto’,表示当样本量与变量个数的乘积大于1200万时不计算样本间距离
verbose:通过该参数设置算法返回日志信息的频度,默认为0,表示不输出日志信息;如果为1,就表示每隔一段时间返回一次日志信息
random_state:用于指定随机数生成器的种子
copy_x:bool类型参数,当参数precompute_distances 为True时有效,如果该参数为True,就表示提前计算距离时不改变原始数据,否则会修改原始数据
n_jobs:用于指定算法运算时使用的CPU数量,默认为1,如果为-1,就表示使用所有可用的CPU
algorithm:用于指定Kmeans的实现算法,可以选择’auto’ ‘full’和’elkan’,默认为’auto’,表示自动根据数据特征选择运算的算法
最佳k值的选择
拐点法
簇内离差平方和拐点法的思想很简单,就是在不同的k值下计算簇内离差平方和,然后通过可视化的方法找到“拐点”所对应的k值。当折线图中的斜率由大突然变小时,并且之后的斜率变化缓慢,则认为突然变化的点就是寻找的目标点,因为继续随着簇数k的增加,聚类效果不再有大的变化。
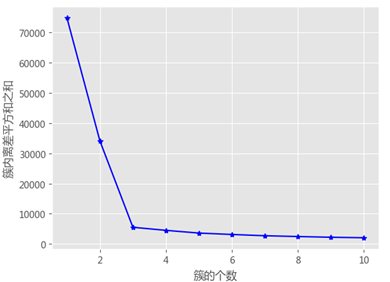
拐点法核心代码
def k_SSE(X, clusters):
# 选择连续的K种不同的值
K = range(1,clusters+1)
# 构建空列表用于存储总的簇内离差平方和
TSSE = []
for k in K:
# 用于存储各个簇内离差平方和
SSE = []
kmeans = KMeans(n_clusters=k)
kmeans.fit(X)
# 返回簇标签
labels = kmeans.labels_
# 返回簇中心
centers = kmeans.cluster_centers_
# 计算各簇样本的离差平方和,并保存到列表中
for label in set(labels):
SSE.append(np.sum((X.loc[labels == label,]-centers[label,:])**2))
# 计算总的簇内离差平方和
TSSE.append(np.sum(SSE))轮廓系数法
该方法综合考虑了簇的密集性与分散性两个信息,如果数据集被分割为理想的k个簇,那么对应的簇内样本会很密集,而簇间样本会很分散。轮廓系数的计算公式可以表示为:
$$
S(i)=\frac{b{(i)}-a(i)}{max(a(i)-b{(i)})}
$$
轮廓系数法中$a(i)$和$b(i)$的计算含义
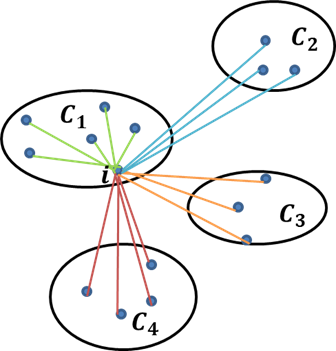
假设数据集被拆分为4个簇,样本i对应的a(i)值就是所有$C_1$中其他样本点与样本i的距离平均值;样本i对应的b(i)值分两步计算,首先计算该点分别到$C_2$、$C_3$和$C_4$中样本点的平均距离,然后将三个平均值中的最小值作为b(i)的度量。
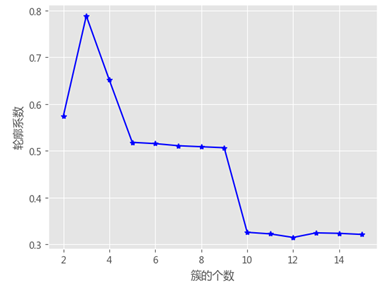
轮廓系数法的核心代码
# 构造自定义函数
def k_silhouette(X, clusters):
K = range(2,clusters+1)
# 构建空列表,用于存储不同簇数下的轮廓系数
S = []
for k in K:
kmeans = KMeans(n_clusters=k)
kmeans.fit(X)
labels = kmeans.labels_
# 调用子模块metrics中的silhouette_score函数,计算轮廓系数
S.append(metrics.silhouette_score(X, labels, metric='euclidean'))Kmeans聚类的应用实战
聚类前的准备
聚类前必须指定具体的簇数k值,如果k值是已知的,可以直接调用cluster子模块中的Kmeans类,对数据集进行分割;如果k值是未知的,可以根据行业经验或前面介绍的三种方法确定合理的k值;
另一个是对原始数据集做必要的标准化处理,由于聚类是基于点之间的距离实现的,所以,如果原始数据集存在量纲上的差异,就必须对其进行标准化的预处理;
# 导入第三方包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn import metrics
%matplotlib inline
# 读取iris数据集
iris = pd.read_csv(r'iris.csv')
# 查看数据集的前几行
iris.head()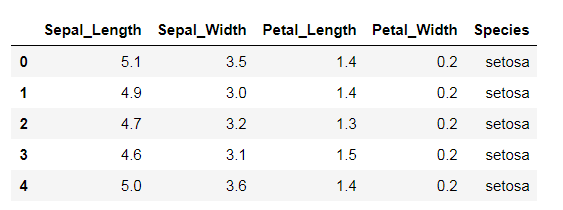
# 提取出用于建模的数据集X
X = iris.drop(labels = 'Species', axis = 1)
# 构建Kmeans模型
kmeans = KMeans(n_clusters = 3)
kmeans.fit(X)
# 聚类结果标签
X['cluster'] = kmeans.labels_
# 各类频数统计
X.cluster.value_counts()
#输出
0 62
1 50
2 38
Name: cluster, dtype: int64
# 导入第三方模块
import seaborn as sns
# 三个簇的簇中心
centers = kmeans.cluster_centers_
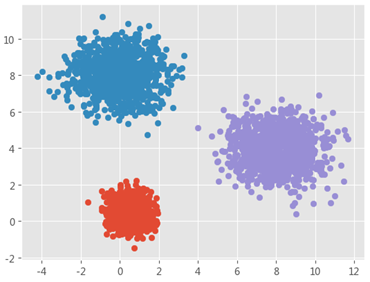
# 绘制聚类效果的散点图
sns.lmplot(x = 'Petal_Length', y = 'Petal_Width', hue = 'cluster',
markers = ['^','s','o'],
data = X, fit_reg = False, scatter_kws = {'alpha':0.8},
legend_out = False)
plt.scatter(centers[:,2], centers[:,3], marker = '*', color = 'black', s = 130)
plt.xlabel('花瓣长度')
plt.ylabel('花瓣宽度')
# 图形显示
plt.show()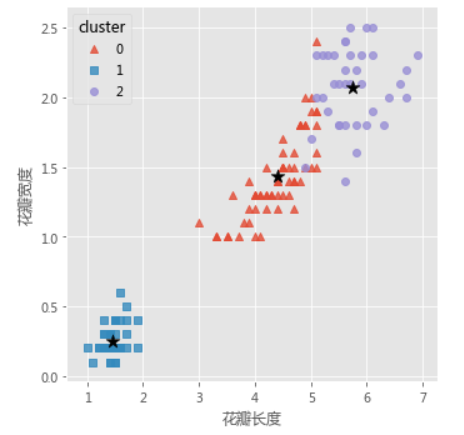
# 导入第三方模块
import pygal
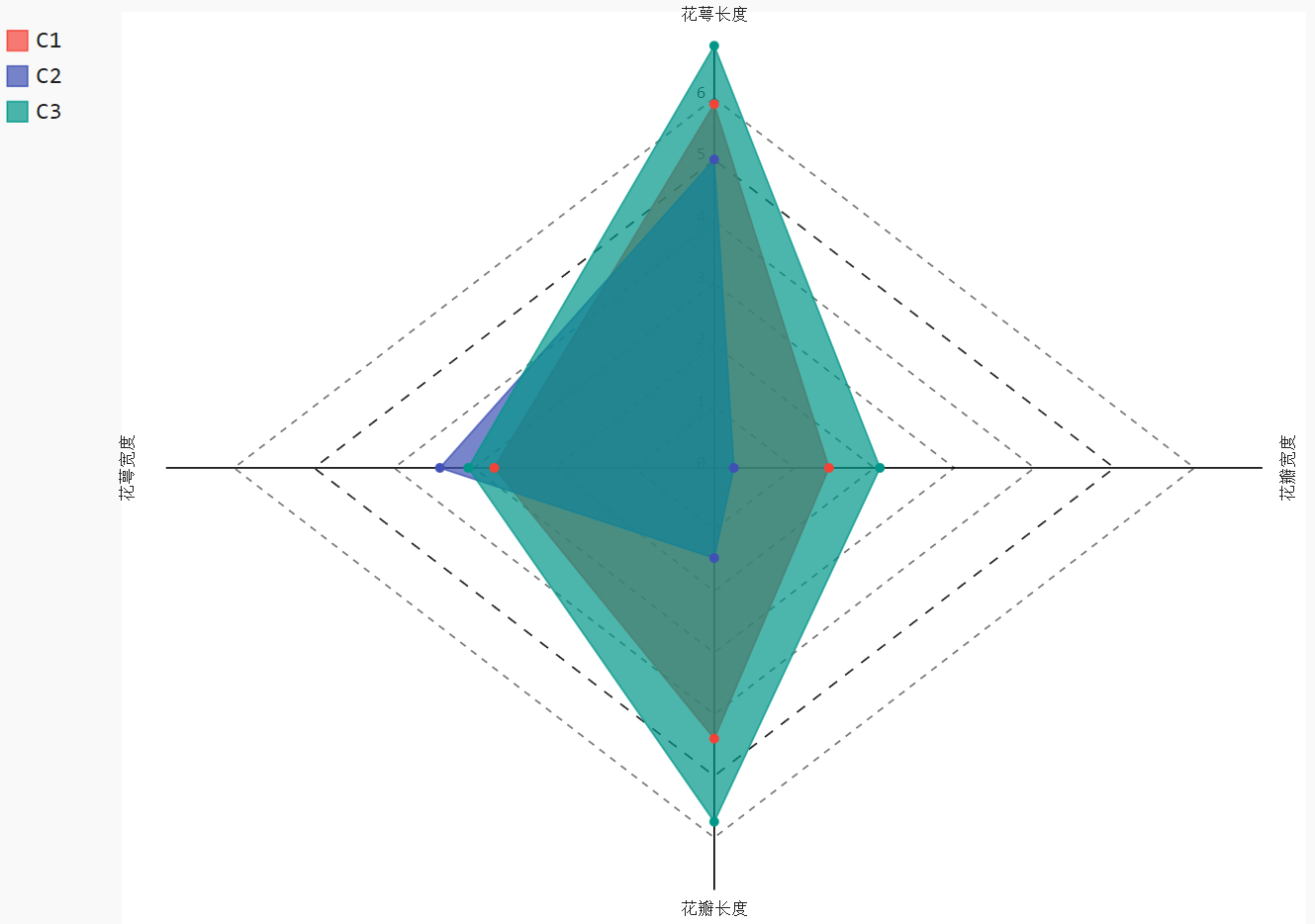
# 调用Radar这个类,并设置雷达图的填充,及数据范围
radar_chart = pygal.Radar(fill = True)
# 添加雷达图各顶点的名称
radar_chart.x_labels = ['花萼长度','花萼宽度','花瓣长度','花瓣宽度']
# 绘制三个雷达图区域,代表三个簇中心的指标值
radar_chart.add('C1', centers[0])
radar_chart.add('C2', centers[1])
radar_chart.add('C3', centers[2])
# 保存图像
# radar_chart.render_to_png('radar_chart.png')
radar_chart.render_to_file('radar_chart.svg')