Presto基础知识总结
公司使用Presto为数据分析师们进行即席查询服务,网上的知识太过碎片化,因此看了《Presto技术内幕》,大体了解一下Presto的知识。国内的Presto社区由JD维护(ps:基本也不咋维护,github上最新的提交时间是5年前),《Presto技术内幕》也出自京东,Presto在国内的很多互联网公司都有应用,在此表示感谢。
本篇文章一方面摘录《Presto技术内幕》的一些片段,另一方面也加入了一些自己的见解(从数据分析角度),有兴趣的小伙伴可以看看。
一 、Presto简介
1.1 Presto的背景与概念
随着经济和科技快速发展,各大企业和公司每天需要处理的数据飞速增加,因此这几年大数据相关的技术突然兴起并且迅速变得火热,大数据开发的岗位需求量也十分巨大。在大数据技术中,无论如何都绕不开Hadoop。Hadoop提供了大数据存储和计算的一整套方案,可以说是非常完美的解决了大数据的存储与计算问题,也是现在所有大数据开发绕不开的技术。但是世界上没有绝对完美的东西,Hadoop提供的大数据解决方案是Google提出的Map-Reduce框架,这种框架适合用于大数据的离线与批量处理,侧重于高吞吐率而非计算效率,因此不能满足大数据快速试试查询的需求。
在这里要说一下Hive, 大家都知道Hive是基于Hadoop的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。Hive数据仓库工具能将结构化的数据文件映射为一张数据库表,并提供SQL查询功能,能将SQL语句转变成MapReduce任务来执行。十分适合数据仓库的统计分析,那Presto相比与Hive有哪些优点?请看1.5节。
Presto是一个使用Java开发的、部署在Linux系统中开源的分布式SQL查询引擎,适用于交互式分析查询,数据量支持GB到PB字节。
按照官方论坛的说法,Presto终结了数据分析的两难选择,即要么使用速度快的昂贵的商业方案,要么使用消耗大量硬件的慢速的“免费”方案。因此Presto的设计和编写完全是为了解决像Facebook这样规模的商业数据仓库的交互式分析和处理速度的问题。
注意:虽然Presto可以解析SQL,但它不是一个标准的数据库。不是MySQL、Oracle的代替品,也不能用来处理在线事务(OLTP)。
1.2 Presto应用场景
Presto是一种基于内存的分布式实时计算框架,经过京东改造过后提供了多种类型的Connector,可以访问包括Hive、MySQL、Cassandra、PostgreSQL、Kafka等多种数据源。作为开发者,可以通过实现Presto标准的SPI接口来定制自己的Connector来达到访问特定数据源的需求。一条Presto查询可以将多个数据源的数据进行合并,可以跨越整个组织进行分析。
应用场景大体有一下几个方面:
ETL
由于Prsto可以方便的支持各种数据源并且支持数据源的混合计算,因此我们是可以用SQL将一个数据源中的数据导入到另一个数据源。例如可以将MySQL中的数据导入到Hive,反之也可以。所以可以通过定时脚本的方式进行ETL
实时数据计算
通过将Hive与Presto配合使用的方式来填补Hive无法满足实时计算的缺点。对海量数据的批处理操作由Hive完成,对海量数据的计算(GB到TB)有Presto完成。
Ad-Hoc查询
即席查询,允许用户根据需求随时调整和选择查询条件,实施返回查询结果或生成报表。与即席查询相对应的是普通查询,因为普通查询是定制开发的,所以可以通过建立索引、分区等优化手段对查询进行优化。即席查询的查询范围等都是未知的,无法对其进行有针对性的优化
对于分析师而言,查询速度是非常重要的!因此Presto主要用来处理响应时间小于1秒到几分钟的场景。
1.3 Presto架构
1.3.1 Presto是由什么组成的
Presto是一个运行在多台服务器上的分布式系统,因此它的架构其实和其他的大数据工具架构都类似,都为主从结构。
Presto集群通常包括一个Coordinator和多个Worker。由客户端提交查询,从Presto命令行CLI提交到Coordinator。Coordinator进行解析,分析并执行查询计划,然后分发处理队列到Worker。
因此Presto有两类服务器:Coordinator和Worker。
1)Coordinator
调度者角色。主要功能就是管理整个Presto集群。
Coordinator服务器是用来解析语句,执行计划分析和管理Presto的Worker结点。Presto安装必须有一个Coordinator和多个Worker。如果用于开发环境和测试,则一个Presto实例可以同时担任这两个角色。
Coordinator跟踪每个Work的活动情况并协调查询语句的执行。Coordinator为每个查询建立模型,模型包含多个Stage,每个Stage再转为Task分发到不同的Worker上执行。
Coordinator与Worker、Client通信是通过REST API。
2)Worker
生产者角色。Worker是负责执行任务和处理数据。Worker从Connector获取数据。Worker之间会交换中间数据。Coordinator是负责从Worker获取结果并返回最终结果给Client。
当Worker启动时,会广播自己去发现 Coordinator,每隔一定的时间也会向Coordinator上的RESTful服务发送心跳,并告知 Coordinator它是可用,随时可以接受Task。
Worker与Coordinator、Worker通信是通过REST API。
1.3.2 Presto是如何组织数据的
1)从结构上看
Presto采取三层表结构:
Catalog:对应某一类数据源,例如Hive的数据,或MySQLql的数据
Schema:对应MySQLql中的数据库
Table:对应MySQLql中的表
1 Connector
Connector是适配器,也可以理解为驱动程序,用于Presto和数据源(如Hive、RDBMS)的连接。你可以认为类似JDBC那样,但却是Presto的SPI的实现,使用标准的API来与不同的数据源交互。
Presto有几个内建Connector,又经过京东改造增加后,现在已经可以满足绝大多数公司的需求。
每个Catalog(介绍在下方)都有一个特定的Connector。如果你使用catelog配置文件,你会发现每个文件都必须包含connector.name属性,用于指定catelog管理器(创建特定的Connector使用)。一个或多个catelog用同样的connector是访问同样的数据库。例如,你有两个Hive集群。你可以在一个Presto集群上配置两个catelog,两个catelog都是用Hive Connector,从而达到可以查询两个Hive集群。
2 Catelog
Presto中的Catelog类似于关系型数据库中的一个数据库实例,而Schema就类似于一个Database,通过使用特定的Connector访问Catelog中指定的数据源,因此Catelog和Schema是一对多,一个Catelog包含Schema和Connector。
例如,你配置MySQL的catelog,通过MySQLConnector访问MySQL信息。当你执行一条SQL语句时,可以同时运行在多个catelog。
Presto处理table时,是通过表的完全限定(fully-qualified)名来找到catelog。例如,一个表的权限定名是Hive.test_data.test,则test是表名,test_data是schema,Hive是catelog。
Catelog的定义文件是在Presto的配置目录中。
3 Schema
Schema类似于关系型数据库中的一个Database,用于组织table。把catelog和schema结合在一起来就唯一确定了可以查询的一系列表的集合。当通过Presto访问Hive或MySQL时,一个schema会同时转为Hive和mySQL的同等概念。
4 Table
Table跟关系型的表定义一样,但数据和表的映射是交给Connector。
2)从存储上看
Presto的存储单元包括:
Page:多行数据的集合,包含多个列的数据,内部仅提供逻辑行,实际以列式存储。
Block:一列数据,根据不同类型的数据,通常采取不同的编码方式,了解这些编码方式,有助于自己的存储系统对接presto。
不同类型的Block:
① Array类型Block,应用于固定宽度的类型,例如int,long,double。block由两部分组成:
boolean valueIsNull[]表示每一行是否有值。
T values[] 每一行的具体值。
② 可变宽度的Block,应用于String类数据,由三部分信息组成
Slice:所有行的数据拼接起来的字符串。
int offsets[]:每一行数据的起始偏移位置。每一行的长度等于下一行的起始便宜减去当前行的起始偏移。
boolean valueIsNull[] 表示某一行是否有值。如果有某一行无值,那么这一行的偏移量等于上一行的偏移量。
③ 固定宽度的String类型的block,所有行的数据拼接成一长串Slice,每一行的长度固定。
④ 字典block:对于某些列,distinct值较少,适合使用字典保存。主要有两部分组成:
字典,可以是任意一种类型的block(甚至可以嵌套一个字典block),block中的每一行按照顺序排序编号。
int ids[]表示每一行数据对应的value在字典中的编号。在查找时,首先找到某一行的id,然后到字典中获取真实的值。
1.3.3 Presto是怎样执行查询的
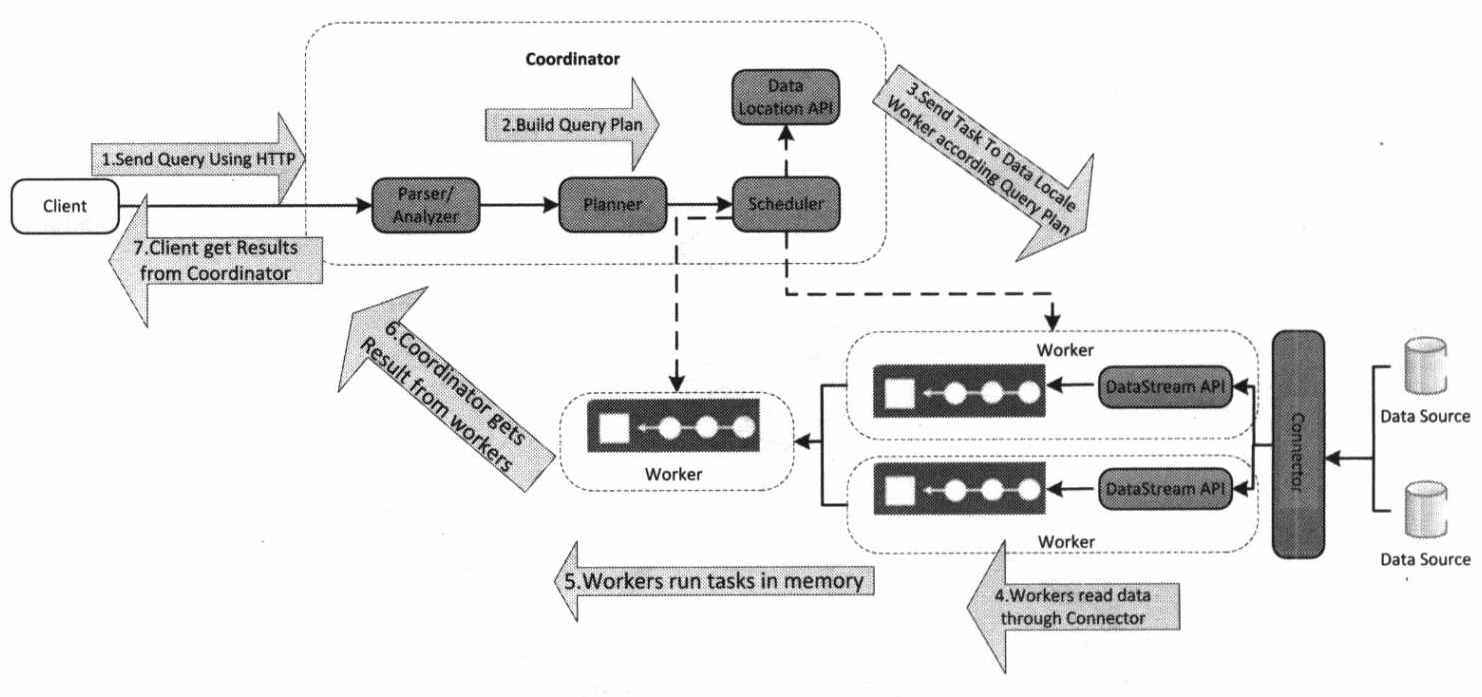
Presto在执行SQL语句时,将这些SQL语句解析为相应的查询,并在分布式集群中执行这些查询。
Statement
statement语句是我们输入的SQL。执行语句时,Presto会创建一个查询以及一个查询计划,然后将这个查询计划生成可以执行的查询Query。分配给一系列Worker。
Query
一个语句可以被认为是传递给Presto的SQL文本,而一个查询是指为了执行该语句而实例化的配置和组件。 查询包含阶段(stage),任务(task),拆分(split),连接器以及其他组件和数据源协同工作以产生结果。Query是由各个Worker 和相关的Stage 组成。Stage
当Presto执行一个查询时,它通过将执行分解为一个阶段层次结构来实现。Stage为树状结构,并不会实际执行。每个查询都有一个根阶段,负责汇总其他阶段的输出, 阶段是协调员用来为分布式查询计划建模的阶段。只是Coordinator进行管理和建模的逻辑概念。Exchange
Stage用来连接另一个Stage。Task
Task是需要实际运行在Presto的各个Worker节点上的。一个Stage被拆分为多个Task,因此可以被并行执行,每个Task处理多个Split,一个Task 又可以分为多个Driver ,从而并行执行一个Task.Driver
一个Task包含一个或多个Driver,是作用于一个Split的一系列Operator的集合,一个Driver处理一个Split。一个Driver拥有一个输入和一个输出。Operator
一个Operator代表一个Split的一种操作,依次读取Split。列如过滤,加权,转换。均会以Page 为最小单位读取输入数据,产生输出数据。Split
一个大的数据集之中的一个小的子集。Presto执行查询时,首先会从Coordinator得到一个表对应的所有Split,然后根据查询计划,选择合适的节点运行Task 处理Split。Page
presto处理的最小数据单元,一个Page对象包含多个Block对象,最大Page为1MB,最多16 * 1024行数据。
总结一下,我们把SQL提交后,Presto会对其进行解析,转换成一个Query。一次查询执行又会被分解为多个Stage,Stage与Stage之间是有前后依赖关系的(树形结构)。每个Stage内部会进一步分解为多个Task,属于每个Stage的Task被均匀的分在了每个Worker上执行(因为有调度者的存在)。每个Task又由一系列前后连接的Operator组成,每个Operator都代表针对于一个Split的操作。可以看出这种层层分解、并行执行的方式也是导致Presto查询速度快的重要因素。
1.4 Presto整体架构
1.4.1 硬件架构
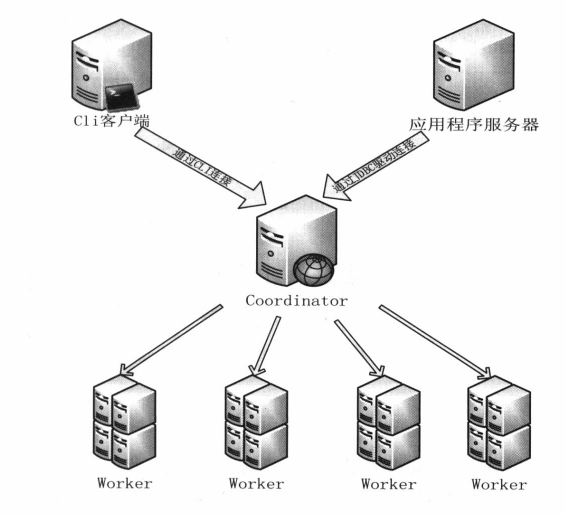
Presto是基于内存的,所以硬件要求很高,集群兴建必须满足大内存、万兆网络。上文提到Presto中的服务主要有两种:Coordinator和Worker,所以也是主从架构。另外还需要一个客户端。
CLI客户端:部署了Presto命令行客户短的服务器
应用客户端:开发人员可以使用JDBC驱动,通过java使用Presto
1.4.2 软件架构
1.5 Presto优缺点
1.5.1 从技术选型上看
由于Presto是基于Java语言开发而且遵循ANSI SQL,因此无论对开发者和使用者来说,presto极易学习使用并准对特定业务场景进行开发和性能优化。个人觉得这一点非常重要,对于一个大的公司来说,采用一个技术往往不仅需要考虑是否满足业务的需求,更要考虑的是使用与学习成本。
1.5.2 从技术本身上看
- 对于多数据源的支持、良好的扩展性
- 简单的数据查询方式,使用者只要会SQL就能直接使用
- 卓越的查询性能
1.5.3 与Hive比较
Hive的本质是把一个查询转化成多个MapReduce任务,然后一个接一个执行。执行的中间结果通过对磁盘的读写来同步。然而Presto没有使用MapReduce,它是通过一个定制的查询和执行引擎来完成的。它的所有的查询处理是在内存中,减少与硬盘的交互,这也是它的性能很高的一个主要原因。
优点
- Presto与Hive对比,都能够处理PB级别的海量数据分析,但Presto是基于内存运算,减少没必要的硬盘IO,所以更快。
- 能够连接多个数据源,跨数据源连表查,如从Hive查询大量网站访问记录,然后从MySQL中匹配出设备信息。
- 部署也比Hive简单,因为Hive是基于HDFS的,需要先部署HDFS。
缺点
- 虽然能够处理PB级别的海量数据分析,但不是代表Presto把PB级别都放在内存中计算的。而是根据场景,如count,avg等聚合运算,是边读数据边计算,再清内存,再读数据再计算,这种耗的内存并不高。但是连表查,就可能产生大量的临时数据,因此速度会变慢,反而Hive此时会更擅长。
- 为了达到实时查询,可能会想到用它直连MySQLql来操作查询,这效率并不会提升,瓶颈依然在MySQLql,此时还引入网络瓶颈,所以会比原本直接操作数据库要慢。



